
Cloud&Heat operates a wide variety of different hardware setups and takes care of the provisioning of computing resources via the security hardened cloud operating system SecuStack. We also continuously optimize our infrastructure in regards to the execution of Machine Learning (ML) workloads. Depending on the use case, we provide a variety of hardware setups by configuring i.e. V100, A100, A10 or T4 graphics cards in conjunction with NVMe block storage, HDD block storage, or with a local SSD. In order to compare different hardware configurations, we use two separate MLCommons benchmarks. With these benchmarks, not only individual components, but rather the entire setup can be tested for its overall performance. The first benchmark is a training benchmark, which trains an ML model for image segmentation. The second is an inference benchmark, which determines the turnaround time of an ML process for image classification and recognition.
Training Benchmark
The benchmark was tested with Linux Ubuntu 20.4 and represents a 3D medical image segmentation task. The model used is a variant of the U-Net3D model, based on the paper “No New-Net” . The dataset (KiTS19) from the Kidney Tumor Segmentation Challenge 2019 is used to train the model.
Overview of the implementation of the benchmark:
First, the Nvidia driver, Nvidia Container Toolkit, Nvidia Docker2 and Docker must be installed.
The corresponding repository must be downloaded from GitHub
git clone https://github.com/mmarcinkiewicz/training.git
The image for the Docker container is created from an existing Dockerfile
docker build unet-3d .
Download the dataset KiTS19.
The data should then be structured as follows:
data
|__ case_00000
| |__ imaging.nii.gz
| |__ segmentation.nii.gz
|__ case_00001
| |__ imaging.nii.gz
| |__ segmentation.nii.gz
...
|__ case_00209
| |__ imaging.nii.gz
| |__ segmentation.nii.gz
|__ kits.jsonThen
sudo docker run
is used to start an interactive session in the container.
Various directories from the Shell are mounted in the container so that there is access to the previously downloaded data.
The previously downloaded data is prepared in the container for the ML process and stored as a NumPy array.
Finally, the ML model will train in the container
bash run_and_time.sh <seed>
This command should be executed for seeds in the range {1..9}, the target accuracy should converge to 0.908.
Quality metric is mean (composite) DICE score for classes 1 (kidney) and 2 (kidney tumor).
Afterwards we measure training time for comparison of the different hardware setups.
Inference Benchmark
The benchmark was tested with Linux Ubuntu 20.4. The COCO (Common Objects in Context) dataset, based on the paper „Microsoft COCO: Common objects in context“, is used. The model is ssd-resnet34, which assigns images from the dataset to a category, e.g. „bottle“. The ssd-resnet-34-1200-onnx model is a multiscale SSD based on the ResNet-34 backbone network and is intended to perform object detection. The model has been trained from the COCO image dataset. This model is pre-trained in the PyTorch framework and converted to ONNX format.
Overview of the implementation of the benchmark:
- This benchmark is not executed in a container like the previous one, so only CUDA must be installed as a basic requirement besides Torch and NumPy
- The corresponding repository must be downloaded from GitHub
git clone https://github.com/mlperf/inference.git - ONNX Runtime ( https://github.com/microsoft/onnxruntime ) is used as ML accelerator
- Then the benchmark is created by executing various Python scripts as defined by the benchmark
- The ML model can be downloaded directly in the terminal
- Annotation and Validation Data are downloaded
- Annotation data is the label data to check the accuracy of the model (.json format)
- Validation data is data with which the model actually processes for evaluation (.jpg format)
- Resolution of the data is increased to 1200*1200, this is a requirement for the ssd-resnet34 model (new format of the validation data: .png)
- Setting of environment variables MODEL_DIR and DATA_DIR, so that the executed bash script knows where the model and the preprocessed data set COCO-1200 are located
- Run the benchmark in the shell with
sudo -E ./run_local.sh onnxruntime ssd-resnet34 gpu- Other ML accelerators can also be used as ONNX Runtime
- Models other than ssd-resnet34 applicable
- Can also run on CPU
- Bash script accepts a variety of commands (e.g. –count; –time; –accuracy)
Functioning of the benchmark:
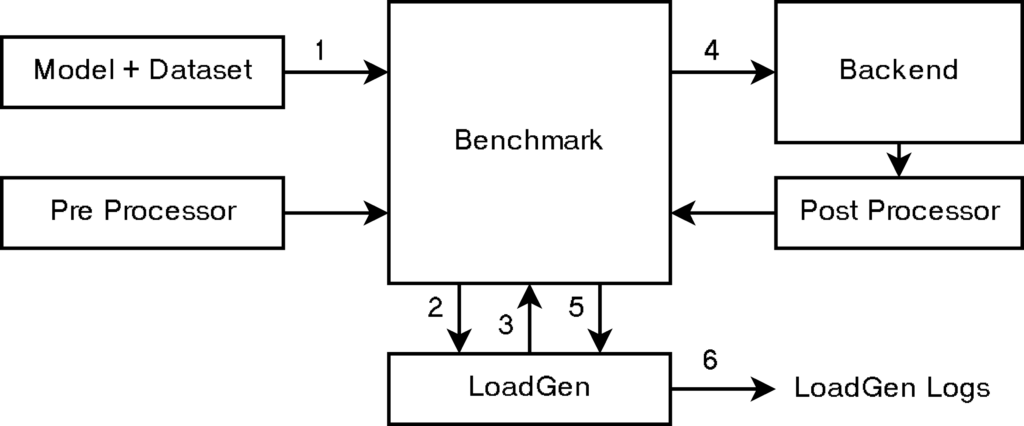
1. Benchmark knows the model, dataset, and preprocessing.
2. Benchmark hands dataset sample IDs to LoadGen.
3. LoadGen starts generating queries of sample IDs.
4. Benchmark creates requests to backend.
5. Result is post processed and forwarded to LoadGen.
6. LoadGen outputs logs for analysis.
If you are interested in a benchmark for your used compute infrastructure, don’t hesitate to contact us.




